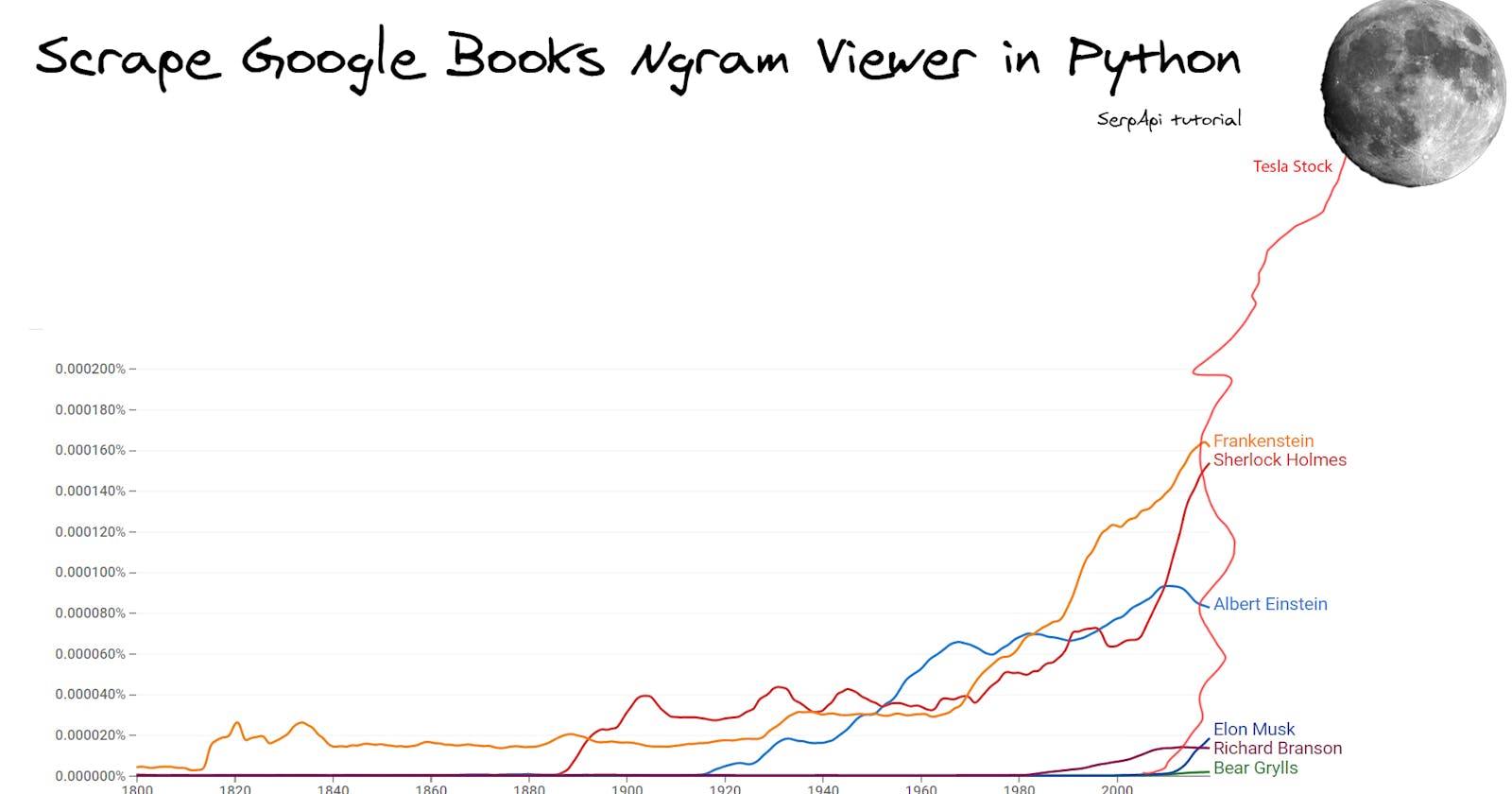
Scrape Google Books Ngrams Viewer in Python
Scrape Google Books Ngrams Viewer and plot time-series plot in Python.


What will be scraped

Comparing with the scraped data plot:

Prerequisites
Separate virtual environment
In short, it's a thing that creates an independent set of installed libraries including different Python versions that can coexist with each other at the same system thus preventing libraries or Python version conflicts.
If you didn't work with a virtual environment before, have a look at the dedicated Python virtual environments tutorial using Virtualenv and Poetry blog post of mine to get familiar.
📌Note: this is not a strict requirement for this blog post.
Install libraries:
pip install requests, pandas, matplotlib, matplotx
Reduce the chance of being blocked
There's a chance that a request might be blocked. Have a look at how to reduce the chance of being blocked while web-scraping, there are eleven methods to bypass blocks from most websites.
Full Code
import requests, matplotx
import pandas as pd
import matplotlib.pyplot as plt
params = {
"content": "Albert Einstein,Sherlock Holmes,Bear Grylls,Frankenstein,Elon Musk,Richard Branson",
"year_start": "1800",
"year_end": "2019"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36",
}
html = requests.get("https://books.google.com/ngrams/json", params=params, headers=headers, timeout=30).text
time_series = pd.read_json(html, typ="series")
year_values = list(range(int(params['year_start']), int(params['year_end']) + 1))
for series in time_series:
plt.plot(year_values, series["timeseries"], label=series["ngram"])
plt.title("Google Books Ngram Viewer", pad=10)
matplotx.line_labels() # https://stackoverflow.com/a/70200546/15164646
plt.xticks(list(range(int(params['year_start']), int(params['year_end']) + 1, 20)))
plt.grid(axis="y", alpha=0.3)
plt.ylabel("%", labelpad=5)
plt.xlabel(f"Year: {params['year_start']}-{params['year_end']}", labelpad=5)
plt.show()
Import libraries:
import requests, matplotx
import pandas as pd
import matplotlib.pyplot as plt
requeststo make a request andmatplotxto customize plot line labels.pandasto read convert JSON string to pandasSerieswhich will be passed tomatplotlibto make a chart.matplotlibto make a time series plot.
Create search query URL parameters and request headers:
# https://docs.python-requests.org/en/master/user/quickstart/#passing-parameters-in-urls
params = {
"content": "Albert Einstein,Sherlock Holmes,Bear Grylls,Frankenstein,Elon Musk,Richard Branson",
"year_start": "1800",
"year_end": "2019"
}
# https://requests.readthedocs.io/en/master/user/quickstart/#custom-headers
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36",
}
User-Agentis used to act as a "real" user visit so websites would think that it's not a bot or a script that sends a request.- Make sure you're using latest
User-Agent. If using oldUser-Agent, websites might treat particular request as a bot or a script that sends a request. Check what's yourUser-Agentat whatismybrowser.com.
Pass search query params, request header to requests and read_json() from returned html:
html = requests.get("https://books.google.com/ngrams/json", params=params, headers=headers, timeout=30).text
time_series = pd.read_json(html, typ="series")
"https://books.google.com/ngrams/json"is a Google Book Ngram Viewer JSON endpoint. The only thing that is being changed in the URL isngrams/graph->ngrams/json. Besides, that, it accepts the same URL parameters asngrams/graph.timeout=30tellsrequseststo stop waiting for a response after 30 seconds.typ="series"tellspandasto make aseriesobject from the JSON string. Default isDataFrame.
Add year values:
# 1800 - 2019
year_values = list(range(int(params['year_start']), int(params['year_end']) + 1))
list()will create alistof values.range()will iterate over a range of values that comes from search queryparams, in this case, from 1800 to 2019.int()will convert string query parameter to an integer.+ 1to get the last value as well, in this case, year 2019, otherwise the last value will be 2018.
Iterate over time_series data and make a plot:
for series in time_series:
plt.plot(year_values, series["timeseries"], label=series["ngram"])
label=labelis a line label on the time-series chart.
Add chart title, labels:
plt.title("Google Books Ngram Viewer", pad=10)
matplotx.line_labels() # https://stackoverflow.com/a/70200546/15164646
plt.xticks(list(range(int(params['year_start']), int(params['year_end']) + 1, 20)))
plt.grid(axis="y", alpha=0.3)
plt.ylabel("%", labelpad=5)
plt.xlabel(f"Year: {params['year_start']}-{params['year_end']}", labelpad=5)
pad=10andlabelpad=5stands for label padding.matplotx.line_labels()will add style labels which will apper on the right side of each line.plt.xticks()is a ticks on X the axis andrange(<code>, 20)where 20 is a step size.grid()is a grid lines, andalphaargument defines a blending (transparency).ylabel()/xlabel()stands for y-axis and x-axis label.
Show plot:
plt.show()
Links
Outro
If you have anything to share, any questions, suggestions, or something that isn't working correctly, feel free to drop a comment in the comment section or reach out via Twitter at @dimitryzub, or @serp_api.
Yours, Dmitriy, and the rest of SerpApi Team.
Join us on Reddit | Twitter | YouTube
Add a Feature Request💫 or a Bug🐞