Implement SEO Cron Jobs with Replit and SerpApi Code


Intro
This blog post will go over how to use an online IDE called Replit and how it could be used as a host option to host your SerpApi code to run cron jobs for your SEO, data extraction script, or anything else.
What is SerpApi?
SerpApi provides a convenient gateway to access raw data from Google and other search engines through JSON responses, meaning whatever you see in Google or other engines you can see in the response JSON.
It has support for 9 languages (and 2 coming soon, Swift and C++). Playground page to play around and experiment.
But why Replit?
Well, it's simpler from pretty much all sides than other similar tools (such as pythonanywhere) and it keeps only getting better and better, at least for now.
A few words about "Always on" feature
Please keep in mind that this example requires at least a Hacker plan that Replit offers, which currently costs $7/month. This plan is required to use of the "Always on" feature. The Replit plan costs $2 more than a pythonanywhere hacker plan, I think it's worth it.
Setting up Replit account and Repl
First, make sure you've registered an account, and then choose a Hacker plan:

Next, we need to create a repl where all code will be added:
Choose Python as a Template, name your repl however you like, make it public or private, and create the repl:

After the repl has been created, here are the main things we'll be touching, the same as in your IDE or text editor pretty much:

Install Packages
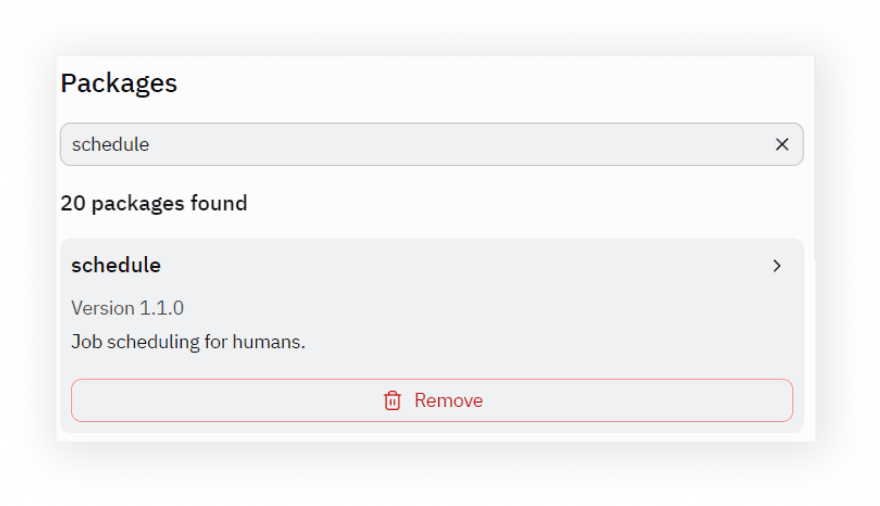
Now to the code itself. Add google-search-results under the "Packages" tool and install it:

Add a schedule package that will do a Cron job:
Code
Here's a very simple example code that runs every 5 seconds until N time and extracts the position of the target website.
Have a look at how the following example runs on Replit, in case you want (you need to change os.getenv("API_KEY") to your SerpApi key).
from serpapi import GoogleSearch
import os
import time
from datetime import datetime, time as datetime_time
import schedule
def job():
TARGET_KEYWORD = 'coffee'
TARGET_WEBSITE = 'healthline.com'
QUERY = 'coffee tips'
params = {
"api_key": os.getenv("API_KEY"), # your serpapi api key, https://serpapi.com/manage-api-key
"engine": "google", # serpapi pareser engine
"location": "Austin, Texas, United States", # location of the search
"q": QUERY, # search query
"gl": "us", # country of the search, https://serpapi.com/google-countries
"hl": "en", # language of the search, https://serpapi.com/google-languages
"num": 100 # 100 results
}
search = GoogleSearch(params)
results = search.get_dict()
matched_results = []
for result in results["organic_results"]:
if TARGET_KEYWORD in result["title"].lower() and TARGET_WEBSITE in result["link"]:
matched_results.append({
"position": result["position"],
"match_title": result["title"],
"match_link": result["link"]
})
print(datetime.now().strftime("%H:%M"))
print(matched_results)
if __name__ == "__main__":
scheduled_off_time = datetime_time(6, 11) # 6 hours, 11 minutes. Repl server local time
schedule.every(5).seconds.until(scheduled_off_time).do(job)
while True:
schedule.run_pending()
print("job pending ⌛")
time.sleep(4)
current_time = datetime.now().time()
if current_time > scheduled_off_time:
schedule.clear()
print("Done ✅")
break
Full execution output
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
https://serpapi.com/search
06:01
[{'position': 75, 'match_title': '8 Ways to Make Your Coffee Super Healthy - Healthline', 'match_link': 'https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy'}]
job pending ⌛
job pending ⌛
job pending ⌛
Done ✅
Returned result:
[
{
"position":75,
"match_title":"8 Ways to Make Your Coffee Super Healthy - Healthline",
"match_link":"https://www.healthline.com/nutrition/8-ways-to-make-your-coffee-super-healthy"
}
]
The one thing I want to emphasize is that make sure you see what the current time at the repl server is by running the command below.
This is to make sure you see what the server's local time is as it might be different from your local one.
from datetime import datetime
datetime.now().strftime("%H:%M:%S") # or without %S, %M
# 05:35:02
Setting up "Always on" feature
In addition to enabling the "Always on" feature, you can also enable "Boost repl" if you need more RAM, CPU, and storage:
GIF
Yay 🎉 Now your script will be always active and run until a certain time 🙂
With this approach, you can add tools such as Google Cloud Storage to extract the data and immediately upload it to the cloud bucket, and a lot other things.
Add a Feature Request💫 or a Bug🐞