


If you're already familiar with how I structure blog posts, then you can jump to what will be scraped section since the Intro, Prerequisites, and Import sections are, for the most part, boilerplate parts.
This blog is suited for users with little web scraping experience.
What is Naver Search
Naver is the most widely used platform in South Korea and it is used there more than Google, based Link Assistant and Croud blog posts.
Intro
This blog post is the first of Naver web scraping series. Here you'll see how to scrape Naver News Results using Python with beautifulsoup, requests, lxml libraries.
Note: This blog post shows how to extract data that is being shown on the screenshot, and don't cover different layout handling (unless said otherwise).
Prerequisites
pip install requests
pip install lxml
pip install beautifulsoup4
Make sure to have a basic knowledge of Python, have a basic idea of the libraries mentioned above, and have a basic understanding of CSS selectors because you'll see mostly usage of select()/select_one() beautifulsoup methods that accept CSS selectors.
Usually, I'm using SelectorGadget extension to grab CSS selectors by clicking on the desired element in the browser. CSS selectors reference, or train on a few examples via CSS Diner.
However, if SelectorGadget can't get the desired element, I use Elements tab via Dev Tools (F12 on a keyboard) to locate and grab CSS selector(s) or other HTML elements.
To test if the selector extracts correct data you can place those CSS selector(s) in SelectorGadget window, or via Dev Tools Console tab using $$(".SELECTOR") which is equivalent to document.querySelectorAll(".SELECTOR") to see if the correct elements are selected.
Imports
import requests, lxml
from bs4 import BeautifulSoup
What will be scraped
All News Results from the first page.

Process
If you don't need an explanation, jump to the code section.
There's not a lot of steps that need to be done, we need to:
- Make a request and save HTML locally.
- Find correct
CSSselectors or HTML elements from where to extract data. - Extract data.
Make a request and save HTML locally
Why save locally?
The main point of this is to make sure that IP won't be banned or blocked for some time, which will delay the script development process.
When requests are being sent constantly (regular user won't do that) from the same IP, this could be detected (tagged or whatever, as unusual behavior) and blocked or banned to secure the website.
Try to save HTML locally first, test everything you need there, and then start making actual requests.
import requests
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"query": "minecraft",
"where": "news",
}
html = requests.get("https://search.naver.com/search.naver", params=params, headers=headers).text
with open(f"{params['query']}_naver_news.html", mode="w") as file:
file.write(html)
What we've done here?
Import a requests library
import requests
Add user-agent
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
Add search query parameters
params = {
"query": "minecraft", # search query
"where": "news", # news results
}
Pass user-agent and query params
Pass user-agent to request headers and, pass query params while making a request.
You can read more in-depth about it in the article I wrote about why it's a good idea to pass user-agent to request header.
After the request is made, then we receive a response which will be decoded via .text.
html = requests.get("https://search.naver.com/search.naver", params=params, headers=headers).text
Save HTML locally
with open(f"{params['query']}_naver_news.html", mode="w") as file:
file.write(html)
# output file will be minecraft_naver_news.html
Find correct selectors or HTML elements
Get a CSS selector of the container with all needed data such as title, link, etc
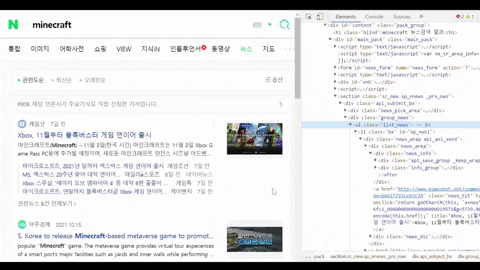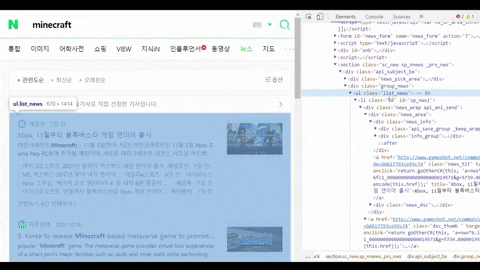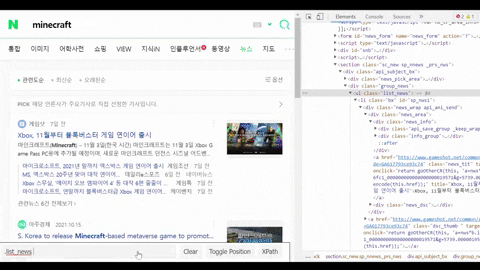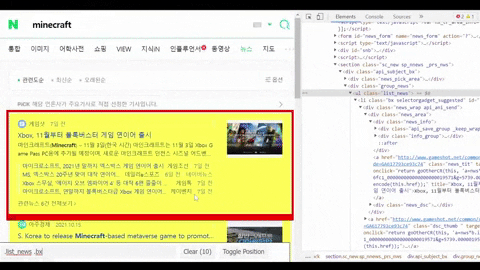
for news_result in soup.select(".list_news .bx"):
# further code
Get a CSS selector for title, link, etc. that will be used in extracting part
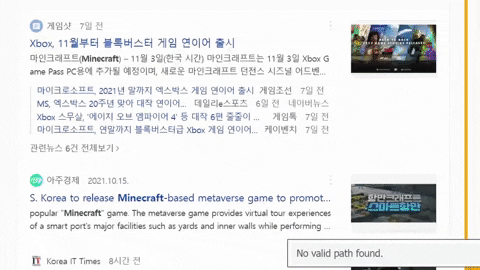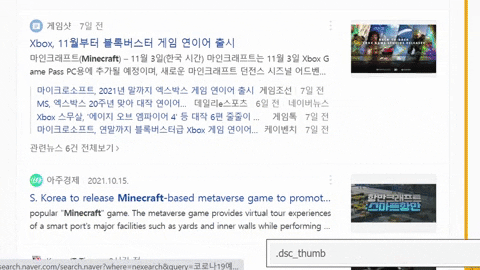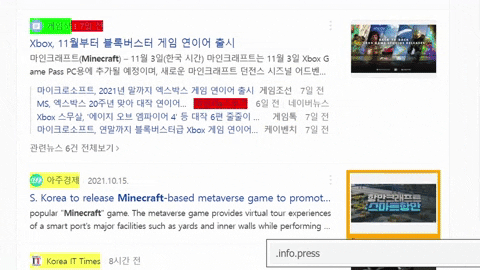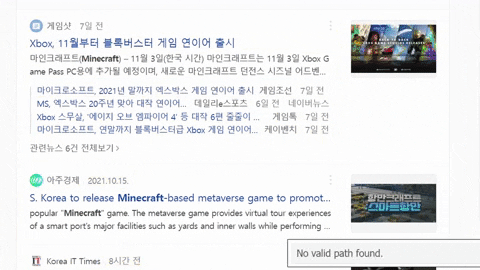
for news_result in soup.select(".list_news .bx"):
# hey, news_results, grab TEXT value from every element with ".news_tit" selector
title = news_result.select_one(".news_tit").text
# hey, news_results, grab href (link) attribute from every element with ".news_tit" selector
link = news_result.select_one(".news_tit")["href"]
# other elements..
Extract data
import lxml, json
from bs4 import BeautifulSoup
with open("minecraft_naver_news.html", mode="r") as html_file:
html = html_file.read()
soup = BeautifulSoup(html, "lxml")
news_data = []
for news_result in soup.select(".list_news .bx"):
title = news_result.select_one(".news_tit").text
link = news_result.select_one(".news_tit")["href"]
thumbnail = news_result.select_one(".dsc_thumb img")["src"]
snippet = news_result.select_one(".news_dsc").text
press_name = news_result.select_one(".info.press").text
news_date = news_result.select_one("span.info").text
news_data.append({
"title": title,
"link": link,
"thumbnail": thumbnail,
"snippet": snippet,
"press_name": press_name,
"news_date": news_date
})
print(json.dumps(news_data, indent=2, ensure_ascii=False))
Now let's see what is going on here.
Import bs4, lxml and json libraries
import lxml, json
from bs4 import BeautifulSoup
Open saved HTML file and pass to BeautifulSoup()
Open saved HTML file and change the mode from writing (mode="w") to reading (mode="r") and pass it to BeautifulSoup() so it can extract elements, and assigned "lxml" as an HTML parser.
with open("minecraft_naver_news.html", mode="r") as html_file:
html = html_file.read() # reading
soup = BeautifulSoup(html, "lxml")
Create list() to temporary store the data
news_data = []
Iterate over container
By container I mean CSS selector that wraps other elements such as title, link, etc. inside itself with all the needed data, and extract it.
# news_data = []
for news_result in soup.select(".list_news .bx"):
title = news_result.select_one(".news_tit").text
link = news_result.select_one(".news_tit")["href"]
thumbnail = news_result.select_one(".dsc_thumb img")["src"]
snippet = news_result.select_one(".news_dsc").text
press_name = news_result.select_one(".info.press").text
news_date = news_result.select_one("span.info").text
Append extracted data as a dictionary to earlier created list()
news_data.append({
"title": title,
"link": link,
"thumbnail": thumbnail,
"snippet": snippet,
"press_name": press_name,
"news_date": news_date
})
Print collected data
Print the data using json.dumps(), which in this case is just for pretty printing purpose.
print(json.dumps(news_data, indent=2, ensure_ascii=False))
# part of the output
'''
[
{
"title": "Xbox, 11월부터 블록버스터 게임 연이어 출시",
"link": "http://www.gameshot.net/common/con_view.php?code=GA617793ce93c74",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fimgnews.pstatic.net%2Fimage%2Forigin%2F5739%2F2021%2F10%2F26%2F19571.jpg&type=ofullfill264_180_gray&expire=2&refresh=true",
"snippet": " 마인크래프트(Minecraft) – 11월 3일(한국 시간) 마인크래프트는 11월 3일 Xbox Game Pass PC용에 추가될 예정이며, 새로운 마인크래프트 던전스 시즈널 어드벤처(Minecraft Dungeons Seasonal Adventures), 동굴과... ",
"press_name": "게임샷",
"news_date": "6일 전"
}
# other results...
]
'''
Call newly added data
for news in news_data:
title = news["title"]
# link, snippet, thumbnail..
print(title)
# prints all titles that was appended to the list()
Full Code
Have a look at the second function that will make an actual request to Naver search with passed query parameters. Test in the online IDE yourself.
import lxml, json, requests
from bs4 import BeautifulSoup
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"query": "minecraft",
"where": "news",
}
# function that parses content from local copy of html
def extract_news_from_html():
with open("minecraft_naver_news.html", mode="r") as html_file:
html = html_file.read()
# calls naver_parser() function to parse the page
data = naver_parser(html)
print(json.dumps(data, indent=2, ensure_ascii=False))
# function that makes an actual request
def extract_naver_news_from_url():
html = requests.get("https://search.naver.com/search.naver", params=params, headers=headers)
# calls naver_parser() function to parse the page
data = naver_parser(html)
print(json.dumps(data, indent=2, ensure_ascii=False))
# parser that accepts html argument from extract_news_from_html() or extract_naver_news_from_url()
def naver_parser(html):
soup = BeautifulSoup(html.text, "lxml")
news_data = []
for news_result in soup.select(".list_news .bx"):
title = news_result.select_one(".news_tit").text
link = news_result.select_one(".news_tit")["href"]
thumbnail = news_result.select_one(".dsc_thumb img")["src"]
snippet = news_result.select_one(".news_dsc").text
press_name = news_result.select_one(".info.press").text
news_date = news_result.select_one("span.info").text
news_data.append({
"title": title,
"link": link,
"thumbnail": thumbnail,
"snippet": snippet,
"press_name": press_name,
"news_date": news_date
})
return news_data
Using Naver News Results API
As an alternative, you can achieve the same by using SerpApi. SerpApi is a paid API with a free plan.
The difference is that there's no need to code the parser from scratch and maintain it overtime (if something will be changed in the HTML), figure out what selectors to use, and how to bypass blocks from search engines.
Install SerpApi library
pip install google-search-results
Example code to integrate:
from serpapi import GoogleSearch
import os, json
params = {
"api_key": os.getenv("API_KEY"),
"engine": "naver",
"query": "Minecraft",
"where": "news"
}
search = GoogleSearch(params) # where extraction happens
results = search.get_dict() # where structured json appears
news_data = []
for news_result in results["news_results"]:
title = news_result["title"]
link = news_result["link"]
thumbnail = news_result["thumbnail"]
snippet = news_result["snippet"]
press_name = news_result["news_info"]["press_name"]
date_news_poseted = news_result["news_info"]["news_date"]
news_data.append({
"title": title,
"link": link,
"thumbnail": thumbnail,
"snippet": snippet,
"press_name": press_name,
"news_date": date_news_poseted
})
print(json.dumps(news_data, indent=2, ensure_ascii=False))
Let's how this code works.
Import serpapi, os, json libraries
from serpapi import GoogleSearch
import os
import json # in this case used for pretty printing
os library stands for operating system (miscellaneous operating system interfaces), and os.getenv(SECRET_KEY) return the value of the environment variable key if it exists.
Define search parameters
Note this parameters will be different depending on what
"engine"you're using (except, in this case,"api_key","query").
params = {
"api_key": os.getenv("API_KEY"), # API key that being stored in the environment variable
"engine": "naver", # search engine
"query": "Minecraft", # search query
"where": "news" # news results filter
# other parameters
}
Create list() to temporary store the data
news_data = []
Iterate over each ["news_resutlts"], and store to the news_data list().
The difference here is that instead of calling some CSS selectors, we're extracting data from the dictionary (provided from SerpApi) by their key.
for news_result in results["news_results"]:
title = news_result["title"]
link = news_result["link"]
thumbnail = news_result["thumbnail"]
snippet = news_result["snippet"]
press_name = news_result["news_info"]["press_name"]
date_news_poseted = news_result["news_info"]["news_date"]
news_data.append({
"title": title,
"link": link,
"thumbnail": thumbnail,
"snippet": snippet,
"press_name": press_name,
"news_date": date_news_poseted
})
Print collected data via json.dumps() to see the output
print(json.dumps(news_data, indent=2, ensure_ascii=False))
---------------
'''
[
{
"title": "Xbox, 11월부터 블록버스터 게임 연이어 출시",
"link": "http://www.gameshot.net/common/con_view.php?code=GA617793ce93c74",
"thumbnail": "https://search.pstatic.net/common/?src=https%3A%2F%2Fimgnews.pstatic.net%2Fimage%2Forigin%2F5739%2F2021%2F10%2F26%2F19571.jpg&type=ofullfill264_180_gray&expire=2&refresh=true",
"snippet": " 마인크래프트(Minecraft) – 11월 3일(한국 시간) 마인크래프트는 11월 3일 Xbox Game Pass PC용에 추가될 예정이며, 새로운 마인크래프트 던전스 시즈널 어드벤처(Minecraft Dungeons Seasonal Adventures), 동굴과... ",
"press_name": "게임샷",
"news_date": "6일 전"
}
# other results...
]
'''
Links
- Code in the online IDE
- Naver News Results API
- SelectorGadget
- An introduction to Naver
- Google Vs. Naver: Why Can’t Google Dominate Search in Korea?
Outro
If you have anything to share, any questions, suggestions, or something that isn't working correctly, feel free to drop a comment in the comment section or reach out via Twitter at @dimitryzub, or @serp_api.
Yours, Dimitry, and the rest of SerpApi Team.